2.9 The 1000 Genomes Project
Where did this sequencing data come from?
In 2015, a study called the 1000 Genomes Project (1KG or 1KGP) sequenced 3,202 individuals from 26 globally diverse populations. Because this data is publicly available, it’s become one of the most widely used datasets in human genetics.
Notably, 1KGP still excludes key regions of the world – such as Oceania, the Middle East, native American populations in North America, and many populations within Africa.
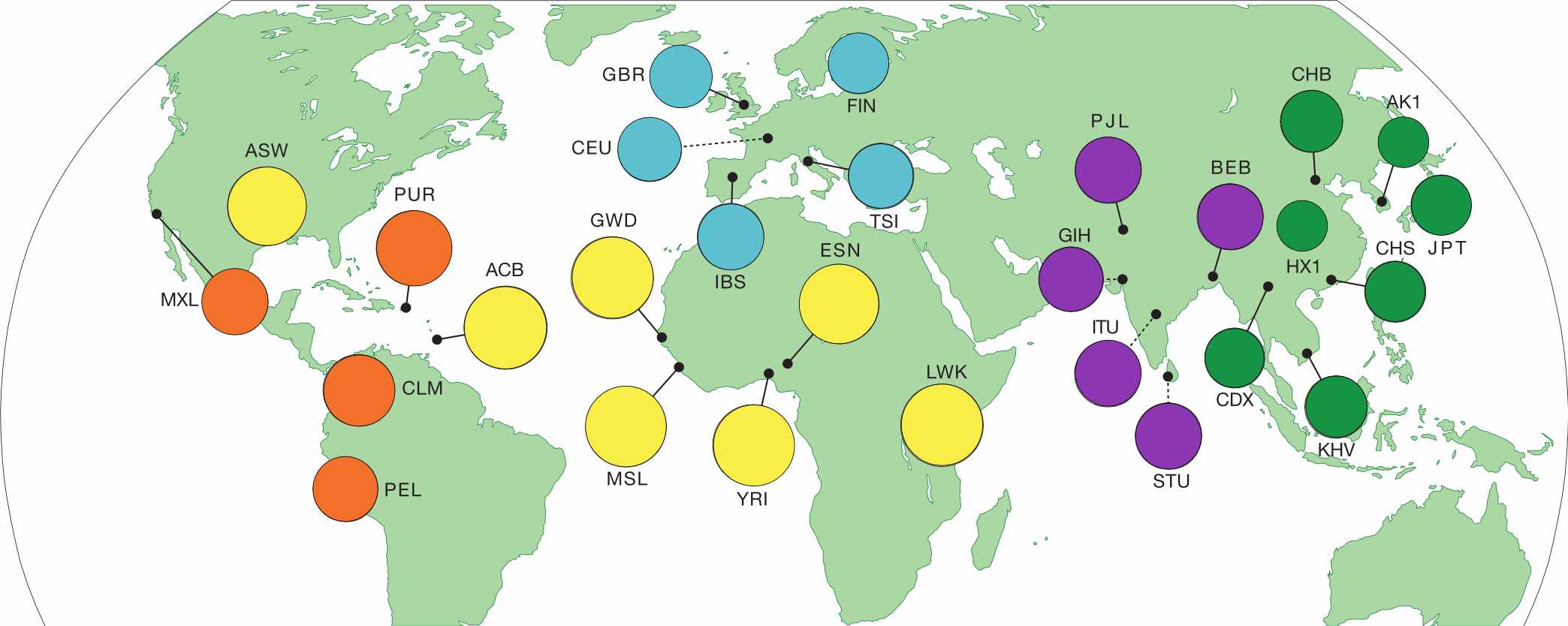
Fig. 14. Regions sampled by the 1000 Genomes Project.
Go to the 1000 Genomes Project website and click the Data tab. Then click the link to the data portal.
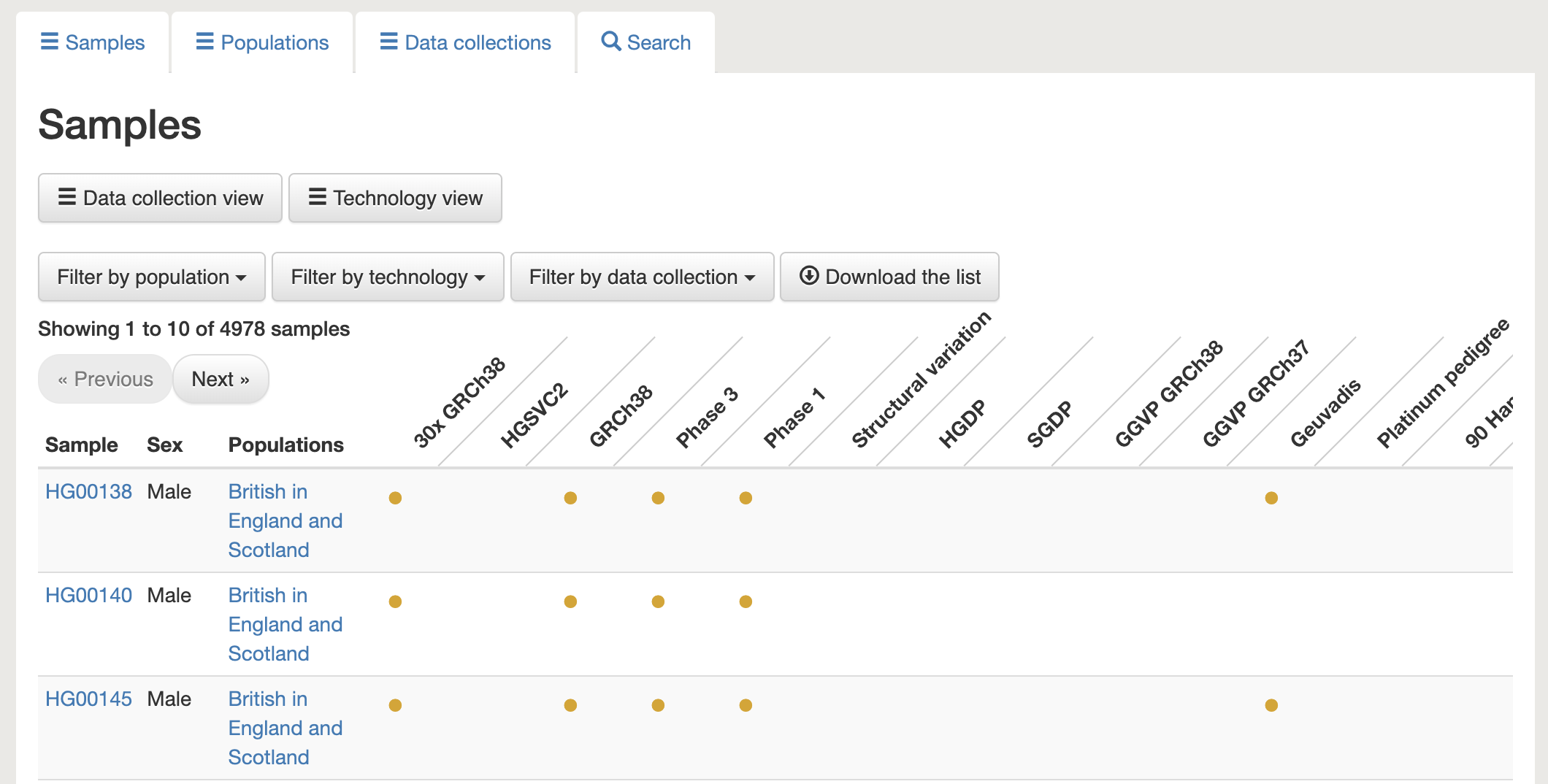
Fig. 15. The data portal includes information about the samples in this dataset.
Choose any individual and copy their sample ID (ex: HG00138). We can use this sample ID to find this individual’s raw sequencing data in the Sequence Read Archive (SRA).